The Logical Core Architecture
by
Tom McKendree
Molecular
Manufacturing Shortcut Group
telephone: (714) 374-2081
fax: (714) 732-2613
[email protected]
This is a draft paper
for a talk at the
Fifth
Foresight Conference on Molecular Nanotechnology.
The final version has been submitted
for publication in the special Conference issue of Nanotechnology.
This page uses the HTML <sup> and
<sub> conventions for superscripts and subscripts. If
"103" looks the same as "103"
then your browser does not support superscripts. If "xi"
looks the same as "xi" then your browser does not
support subscripts. Failure to support superscripts or
subscripts can lead to confusion in the following text,
particularly in interpreting exponents.
Table of Contents
Molecular nanotechnology (MNT) promises new function for
engineered systems, such as fairly general purpose fabrication
and disassembly. Systems designing afresh to take advantage of
these new functions should offer original architectures. One
compelling example is the "logical core architecture,"
which uses subsystems providing general purpose manufacturing to
enable a long-lived, very flexible system.
This paper provides motivation for the logical core
architecture, discussing systems architecting, the inclination of
MNT to support polymorphic systems, and the implications of using
dynamic remanufacture of on-board components for reliability. It
describes in detail the logical core architecture, which
comprises four levels, the logical core, the physical core, the
surge layer, and the external interface layer. The functions of
the subsystems in each of these layers are presented.
To illuminate the architecture's capabilities, example
operations are presented. Several are space mission profiles for
systems using a logical core architecture for such tasks as
multi-mode trajectories and asteroid mining, and several
illustrate more general capabilities and flexibilities of the
architecture. Basic equations are derived for reliability through
on-board remanufacture of subcomponents and for surging
functional capacity.
The prospect of fundamentally new operating modes raises
interesting questions regarding appropriate operating policies.
The paper concludes with a discussion of important open
questions, including appropriate directions for further stepwise
refinement of the architecture.
Effective systems have overall structures, or architectures,
that are well matched to the capabilities of their implementing
technologies. Molecular Nanotechnology (MNT), examined in [Drexler,
1992a], is an impending technology that should offer radical
changes in capabilities. This suggests that it should lead to
novel effective architectures.
This paper presents an attractive architecture for exploiting
MNT, to further our understanding of the future world that MNT
will bring. One aspect of this world is that it should provide
much stronger capabilities for space operations at must lower
costs [Drexler, 1986a],
[Drexler, 1986b], [Drexler, 1988a], [Drexler, 1992b], [Drexler,
1995], [McKendree,
1996], [McKendree, 1997a]. As a result, operations in space
should be a much larger part of this future world than they are
today. Accordingly, this paper focuses on space applications of
MNT, and specific examples in this paper come from that field. By
illustrating various operational concepts for space missions, we
can begin to understand the options that can help us consider
overall strategies for using MNT in space. Much as a von Neumann
architecture computer can be used for more than computing
ballistic trajectories, however, logical core architecture
systems will have important applications beyond space operations.
The foreseen characteristics of MNT indicate likely
characteristics of systems that well exploit MNT. These desirable
characteristics help lead to the architecture defined in section 3.
Molecular nanotechnology (MNT) promises substantial increases
in the quantitative performance of established functions, and the
ability to perform qualitatively new functions [Drexler,
1992a]. Any dramatic increase in technical performance opens
the potential for fundamentally new system architectures
[McKendree, 1992]. Given the tremendous new capabilities MNT
offers, Dr. Axelband [Axelband, 1994] asked for an example of an
original architecture MNT could enable. The Logical Core
Architecture was developed in response to that question.
A novel function offers the best chance for enabling a novel
architecture, and MNT offers the novel function of flexible,
programmable manufacturing, with the added convenience of
high-speed. A reasonable approach is to try to design a system to
heavily exploit this novel function. The Logical Core
Architecture follows this approach.
Technologies have characteristics which predispose them
towards certain types of architectures. Digital microchips seem
predisposed towards dispersing, and often embedding, programmed
intelligence. Petroleum-fueled internal combustion engines seem
predisposed towards self-contained, moderately high speed
vehicles. Early concept exploration suggests MNT may be
predisposed towards polymorphic systems.
[Hall,
1996] suggests using MNT for a scheme of microscopic robots
coordinating to simulate virtually any environment, and able to
rapidly reconfigure assemblies into nearly any simple macroscopic
object. [Thorson, 1991] suggests somewhat similar assemblies of
tiny machines that flexibly coordinate to form human-scale
objects. Systems of flexibly used space-filling cubes have been
suggested [Michael, 94],[Bishop, 95]. [Drexler et. al,
1991] suggested paints and cloth that change their
appearance, tents that unfold themselves and become rigid, and
furniture and clothing that changes their shape and appearance.
All of these MNT-based concepts are polymorphic systems.
So, if one were to look for a fundamentally new system
architectures using MNT, a compelling place to look would be to
take this apparent predisposition of MNT to support architectures
that can reconfigure themselves, and see how far one can push
this characteristic. The Logical Core Architecture follows this
approach.
Consider a system, such as a spacecraft far from Earth. Highly
reliable components can support system reliability. Multiple,
redundant components and subsystems can support further system
reliability. Components will still fail, however, and even with
redundancy, unfailed components will eventually run out. On-board
remanufacture of failed components allows them to be replaced
beyond the supply of any stockpile, providing the potential for
even greater system reliability. This requires an on-board
manufacturing system sufficiently flexible to build all the
components in the system, but MNT offers very flexible molecular
manufacturing [Drexler,
1992a], which appears sufficient for this task.
If using an on-board ability to fabricate and replace some
components as a way to increase reliability, a question becomes
which components of the system should be replaceable?
Certainly, any components with an intrinsically high failure
rate should be replaceable. This includes components that cannot
be made highly reliable, and components that must be used in a
damaging environment. One could imagine a fixed collection of
complex machinery, with light bulbs, tool bits, and consumable
fluids regularly replaced.
While replacing fragile and high-wear items on equipment is
helpful, the machinery itself undergoes slow wear. Eventually,
machines will fail in ways that cannot be repaired simply by
replacing one of their more commonly failing components. One
could imagine a variety of equipment positioned on a structural
framework, and over long periods each being replaced on occasion.
Even dumb structural material will lose desirable material
properties over time, however, from radiation damage if nothing
else. For very high reliability, all the components of the
physical framework should, at some time, be capable of
replacement.
Every physical component is subject to degradation over time.
Therefore every physical component of the system should ideally
be subject to replacement from on-board remanufacture. If one
imagines a system comprised entirely of components that can be
created and replaced on-board, then what is the essence, the
fixed framework, the unchanging core, of the system? It is not
any physical element, but rather the system's logical structure.
The insight that a purely logical heart is desirable is the point
of departure for the logical core architecture.
The logical core architecture is a system structure, defining
relationship between physical elements based on their functional
characteristics, arranging a system into four layers, described
below.
This description of the logical core architecture works from
the inside out, starting with the logical core layer, and
building out to the interface layer. It is this outermost layer
that performs the desired systems functions. The first three
layers serve to maintain system integrity and lifetime while
supporting the interface layer, which performs the system's
intended functions.
Figure 1 illustrates the architecture.
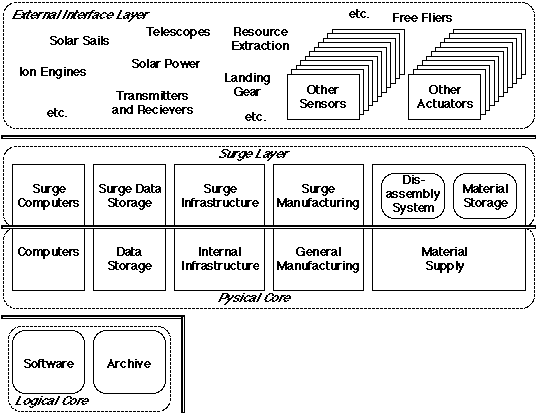
Figure 1. The Layers and Subsystems of the Logical
Core Architecture.
The unchanging heart, the core of the system, is purely
logical. The system operates under control of software running
on-board. The system maintains and draws from a data archive.
Given two otherwise physically identical copies of a logical core
architecture system, with different software and data, they could
be radically different systems with radically different
behaviors.
Actual software code may be running, or in the Archive.
Elements of code flow between the Archive and Software. For
example, the machine could build a large hardware neural net, and
decompress a stored data file with the precomputed neural net
weights for a particular function.
An actual implementation of the logical core architecture may
require software of greater size and complexity than is feasible
today. Actual running code is not needed, however, before
molecular manufacturing is itself feasible. Advances in software
development, and in available computer hardware, should ease the
challenge of developing the necessary software when the time
comes.
Data erased is lost forever, so there is a bias towards saving
data, even if in highly compressed forms.
This architecture does not specify many lower level details.
For example, software may be partitioned functionally, and
protected from cross-contamination.
The physical core consists of the minimal set of subsystems
that implement the logical core, including the minimal support
subsystems necessary to implement the entire logical core
architecture. Computers run the logical core layer software. Data
Storage stores the logical core layer archive. Internal
Infrastructure provides the necessary system support and
maintenance functions. General Manufacturing provides an on-call
ability to build any potential components of the system. Material
Supply provides General Manufacturing with the raw materials it
needs to produce.
This is the physical hardware that runs the logical core
Software. Many lower level details are unspecified. For example,
different functions will likely be assigned to different physical
computers, running in parallel, and potentially dispersed across
the system. To best support different functions, a mixture of
different hardware types may be used.
This is the physical hardware that stores the data in Archive.
The hardware may be physically distributed. There probably will
be different levels of storage. Some data will be frequently
accessed, whereas at the other extreme there will probably be a
large amount of data for mission contingencies, much of which
ultimately may never be accessed.
Since the Archive contains the essence of the system content,
it requires very high reliability from Data Storage. The data
should be redundantly stored using error-correcting contextual
coding, not just simple multiple copy redundancy. The data should
be continually monitoring, and when found errors should be
repaired.
This is the physical equipment that keeps the system
operating. It includes internal distribution of power, heat,
communications, and material. It includes the physical structure
that provides structural stability. It includes internal
manipulation of physical parts, including removal of old or
failed components and installation of new components. It includes
internal power storage. Any hardware required for internal system
operations, not included in other physical core subsystems, is
included in the internal infrastructure.
This subsystem takes feedstock materials, and produces on
demand components of the system. These may be replacement
components, for scheduled maintenance or to replace failed
components. These may instead be physical instantiations of
"virtual" components made available to execute some
purpose.
General Manufacturing need not be "general purpose"
in the sense that it can make literally anything. It needs to be
"general purpose" in the sense that it can build the
full range of components expressed or envisioned in the mission
life of the system embodying the logical core architecture.
Manufacturing can be direct, by building the item, or indirect,
by building another machine, which in turn might building other
machines, and so on, until there the final machine builds the
desired item.
Using molecular nanotechnology to implement a logical core
architecture system, it is envisioned that General Manufacturing
may look something like the exemplar architecture in chapter 14
of Nanosystems [Drexler,
1992a].
This capability creates one of most important characteristics
about logical core architecture systems--they can include virtual
subsystems. Virtual subsystems need not have continuous physical
existence--they can be created on the spot to perform specific
functions. The potential of virtual subsystems radically
transforms operational concepts.
For example, such a system need not actually carry every
subsystem necessary to overcome every threat to its mission; it
need only be able to make them quickly enough on the fly. The
feasibility of this for particular cases will depend primarily on
the relative timing between threat warning and the response time
of subsystem fabrication and set-up. With reference to the
Archive, it is worth noting that set-up times can often be
dramatically reduced if many of the set-up characteristics are
appropriately prestored.
This system provides feedstock materials to General
Manufacturing. It can operate in either or both of two modes, and
move between these modes over the mission life. The first mode is
to maintain stores of various materials (e.g., ingots of
graphite, tanks of helium and acetone, etc.), and feed those
materials to General Manufacturing on demand.
Without recycling, this first mode can only continue until the
stores are used up. Thus, Material Supply needs to be able to
disassemble unneeded components, returning the material to the
stores.
Components should be designed for easy disassembly where
possible, however many unneeded components will be failed, with
improperly placed atoms. Thus, material supply will also need the
ability at some low rate to disassemble components with arbitrary
failure densities. One approach is to ionize the material in a
solar furnace, and separate the elements through mass
spectroscopy. Less extreme approaches should often be feasible.
Note, some power storage is embodied in the fact that most of
the materials will require energy to disassemble, but will
provide energy when assembled.
The need for disassembly points to the second operating mode
for material supply. Here, physical components of the system are
disassembled on the fly, and material from that disassembly is
sent directly to General Manufacturing for use. If the old and
new components are not in elemental balance, this requires
storing the excess material being liberated from the old
components.
The feasibility of this second mode means that the system
could go through a period where it had no stores, everything was
part of some subsystem, but disassembly equipment stood at the
ready, and the system as a whole could continue its full range of
operations afterwards.
While an attractive design goal for the system is the
capability of storing all chemical elements, it may still provide
operationally beneficial in some missions for the system to dump
unwanted material.
The physical core includes General Manufacturing. This allows
the system to build additional capacity in any of its core layer
functions.
If the system is going to be subjected to a larger heat load,
from a solar fly-by for example, extra shading and cooling can be
built. If the vehicle is going to experience an increased
acceleration load (e.g., high acceleration, or tidal forces on a
close flyby of a massive body), then the structural frame and
components could be strengthened.
Main data in the Archive of the logical core is intended to
survive the mission life. Nonetheless, additional data could be
generated, cached, used, and deleted. For example, a major means
of increasing computational speed is using look-up tables. Before
a mission phase that requires significant real-time computation,
such as maneuvering quickly through a chaotic regime, the system
could precompute tables based on formulas in the data archive,
use those tables, and then delete them, saving the basic
formulas.
Since computation can similarly be surged, an appropriate
policy to prepare information for the Archive will often be to
use a massively unsymmetric data compression algorithm, where it
may be computationally intensive to preprocess the data, but
where the stored data can quick and easy be extracted.
General Manufacturing could even surge the capacity of General
Manufacturing. A standard operating mode might be to stand ready
with a small amount of the most flexible manufacturing capacity,
and on request build special purpose manufacturing systems that
then build the desired component.
When disassembling large portions of the system after a
mission phase, the disassembly equipment from Material Supply
could be surged to do this more quickly, with specialized
equipment tuned to the equipment being disassembled.
The External Interface layer consists of all the devices
necessary for the system to interact with its environment to
accomplish its mission. This includes both elements physically in
existence, and virtual elements, built when needed and
disassembled after use. The minimal set of devices for the
External Interface layer is set by the mission. A more general
system would store in its data archive the information to produce
many potential devices, and then select the appropriate subset
for a given mission.
When using a logical core architecture to perform space
missions, potential interface layer devices include solar sails,
solar-electric ion engines, closed environment life support
systems, space colonies, telescopes, signaling lasers, Solar
Power Satellites, surface landers, free-flier probes, wings,
"seeds" (daughter systems and temporary doubles), skin,
and massively et cetera. Using MNT, many of these devices could
perform much better than current equivalents [Drexler, 1986a], [Drexler,
1986b], [Drexler, 1988a], [Drexler, 1992b], [Drexler, 1995], [McKendree,
1996], [McKendree, 1997a].
If the External Interface contains a device that can
disassemble some materials found in the environment, rendering
them into a form usable by Material Supply, then the system can
increase its material content by "eating" those
resources. If the External Interface contains devices that can
disassemble all the material found in some object, an asteroid
for example, then it can totally consume that object, turning
that object into a larger version of the system.
To start exploring the envelope of capabilities which a
logical core architecture system should be able to perform,
various feasible operations are outlined below. Equations are
derived for the first two operations, repair through on-board
remanufacture and surge computation, and the other operations are
described qualitatively.
A major purpose of the logical core architecture is to enable
greater system reliability through on-board remanufacture of
components. Rebuilding components and replacing worn or failed
components on-board are feasible operations.
While analysis of reliability through redundancy is well
understood, the mathematics of reliability through on-board
repair needs development.
One approach is simulation. Since repair through on-board
remanufacture should enable very long mission lives, however,
this could result in very long simulation times. The challenge is
less with event-based simulation, but as simulated time may
exceed the current age of the universe in some cases, the
challenge is still substantial.
Instead, the capabilities are illustrated here with the
following simple model. Assume the system's Physical Core Layer
contains one manufacturing subsystem, and one infrastructure
subsystem. The Surge Layer contains one complete, redundant
manufacturing subsystem, and one complete, redundant
infrastructure subsystem. The manufacturing subsystems and the
infrastructure subsystems are identical, so the distinction
between the Physical Core and the Surge Layers is ignored in this
example. This is the simplest case to illustrate redundancy.
Upon failure of a manufacturing or infrastructure subsystem,
Manufacturing builds a replacement, and Infrastructure installs
the replacement.
The behavior of this system can be analyzed with a metastable
Markov model. (One oversimplification of this approach is that
any time dependency in the probabilities of specific transitions
is lost.) The probability distribution between the states from
which the system potentially can fully repair itself, given that
it is in one of these states, is captured in the following
equations:
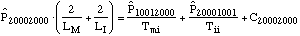 ....(1) ....(1)
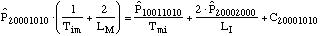 ....(2) ....(2)
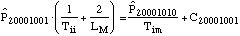 ....(3) ....(3)
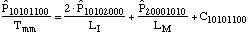 ....(4) ....(4)
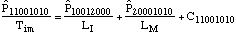 ....(5) ....(5)
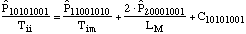 ....(6) ....(6)
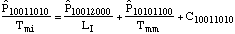 ....(7) ....(7)
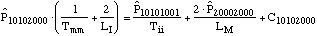 ....(8) ....(8)
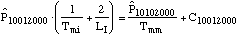 ....(9) ....(9)
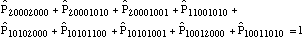 ....(10) ....(10)
The system state is defined by eight state
variables, shown in the subscripts. The first is the number of
unfailed manufacturing systems. Second is the number of failed
manufacturing systems waiting for an available manufacturing
system so it can be rebuilt. Third is the number of failed
manufacturing systems being rebuilt. Fourth is the number of
rebuilt manufacturing systems being installed. Fifth is the
number of unfailed infrastructure systems. Sixth is the number of
failed infrastructure systems waiting for an available
manufacturing system so it can be rebuilt. Seventh is the number
of failed infrastructure systems being rebuilt. Eighth is the
number of rebuilt infrastructure systems being installed.
The Cnnnnnnnn variables are correction terms, which
adjust for the potential for transitions to the other system
states, all of which are fatal to the system. The transition
distributions are exponentially distributed. This is a very
conservative assumption. In practice, if one imagines a
manufacturing subsystem analogous to the exemplar architecture in
[Drexler,
1992a], then the failure probability is very low in the early
part of the system lifetime; a policy of scheduled remanufacture
and replacement, in addition to remanufacture and replacement on
failure, could significantly increase system life beyond what is
calculated here.
Table 1 gives illustrative system lives. "Life"
refers to the expected period that each individual manufacturing
and infrastructure subsystem would survive before failure. That
life is reset for each subsystem every time it is rebuilt.
Table 1. Illustrative system lifetimes in
years, and percent of time system is totally unfailed, for the
M=2, I=2 system.
| Life\Repair Time |
1 Hour |
10 Hours |
100 Hours |
| 1 Month (30 days) |
7.413
98.90% |
0.764
89.68% |
0.110
41.50% |
| 1 Year (356 days) |
1094.52
99.91% |
109.68
99.09% |
11.24
91.41% |
| 10 Years (3562 days) |
109,549.9
99.99% |
10,957.2
99.91% |
1098.0
99.09% |
On-board repair can dramatically extend total system life
beyond what is feasible with simple redundancy. Very long life
depends on having a very low probability of failure for the
remaining manufacturing or infrastructure subsystems, during the
period it takes to rebuild and reinstall a failed subsystem.
One of the most general concepts of the logical core
architecture is "surge" performance. By using on-board
manufacturing, large amounts of physical hardware to fully
accomplish some function can be built, creating a significant
temporary increase in the system's ability to perform that
function.
To illustrate surge potential, the simplest case is used, of a
subsystem with capacity related linearly to subsystem mass. To
help make the idea concrete, the function of computation of a
problem of known computational demand, running an algorithm that
implicitly is massively parallelizable, is shown.
Equations of the form below are applicable to any function
where capacity equals subsystem mass. This general approach of
surging capacity to provide extra capacity at certain times in a
mission can be used for many other purposes. In many cases, the
relationship between system mass and system performance will be
non-linear, even step functions in some cases, and equations of
surge function equivalent to those below will have significantly
different form.
Assume a computer of power (instructions per second) ofCg,
and a problem of estimated size P (instructions). The estimated
run time is merely:
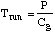 ....(11) ....(11)
The general manufacturing available in the
logical core architecture and other potential MNT-based systems,
however, can be used to build additional computer power. If there
is G general manufacturing capacity (in mass of product per unit
time), used to produce more general computing power as a density
of  instructions per
second per gram, and taking a period of Tcycle from
start until the first manufacturing is complete, then the period
to solve a problem of size P can be estimated as: instructions per
second per gram, and taking a period of Tcycle from
start until the first manufacturing is complete, then the period
to solve a problem of size P can be estimated as:
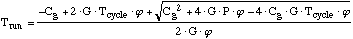 ....(12) ....(12)
For ..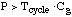 , ,
or ..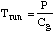 ..for .. ..for ..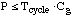
If P>>Tcycle x Cg,
then there is a strong incentive to build significant additional
computational capacity to help solve the problem. If building
additional computational capacity to solve a particular problem,
however, then it makes sense to build special-purpose computers
to particularly solve the problem. While the details vary by
problem, [Moravec, 1988] suggests that a 1000-1 advantage with
special purpose computation is a reasonable rule of thumb.
Assume, therefore, that the additional computational capacity
built is special purpose, with the ability to perform an
equivalent number of instructions per second per gram on this
problem of s.
(This probably represents a smaller number of instructions per
second, but significantly more powerful instructions.) Estimating
Trun only requires replacing in equation (12) above with s:
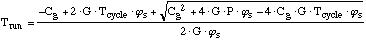 ....(13) ....(13)
For ..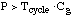 , ,
or . 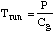 ..for ... ..for ...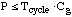
The strategy embodied in equation (13) is to
begin working on the problem, and meanwhile devote the
fabrication capacity fully to building further computational
capacity, which begins to contribute to the calculations as soon
as it is built. The result is a linear increase in computational
capacity with time, and a parabolic increase in computations over
time.
Within an MNT-based system such as the logical core
architecture, the manufacturing can be used to surge the amount
of any subsystem. This includes manufacturing itself. By first
building more manufacturing capacity, and only after some
exponential buildup then building more computational capacity,
the time to complete some very large problems can be greatly
reduced. Let Tcyclem be the period it takes for a
level of manufacturing to build the equivalent additional
capacity. Let Tbuildm be the period spent building up
manufacturing capacity before switching over to building
computational capacity. The problem size, P, that is solved in
time Trun, is then approximately:
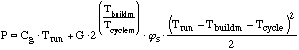 ....(14) ....(14)
For ..
The actual function of productive capacity with
time, buried within the second term of (14), may be stepwise
discontinuous, but for small enough steps (which seem reasonable
for large systems built using molecular nanotechnology) the
continuous exponential growth implied in (14) is a reasonable
approximation.
Since the specialized computation expressed by s is more
productive than the general purpose computation expressed as Cg,
and furthermore, when solving large problems the produced
computational equipment will greatly exceed the pre-existing
computational equipment, the first term in (14) is small for
large problems. Dropping that term allows an analytic solution to
the optimum Tbuild:
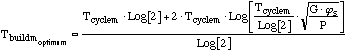 ....(15) ....(15)
Substituting that term into (14) and solving for
Trun gives an estimate for the run time using this
build then solve strategy, as a function of problem size:
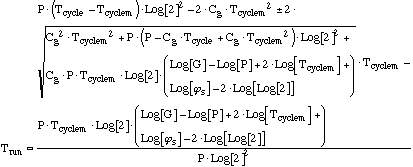 ....(16) ....(16)
With an algorithm based on building additional
computing capability, however, and especially when the algorithm
relies on exponential growth, there is a real danger of
overgrowing available resources for building the computers before
being able to follow a plan for a very large computation. This
can be addressed by setting a total mass, Mbudget,
available for use. Assume for simplicity that this mass is
directly interchangeable between manufacturing and computers.
This means that equation (16) remains valid as long as
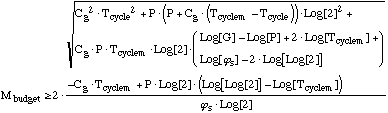 ....(17) ....(17)
This now raises an interesting question. If the desired surge
manufacturing and computational capacity to solve a problem
exceeds the mass budget, how should the budget be partitioned
over time between manufacturing and computation? For somewhat
oversized problems, the likely strategy is to build less
manufacturing capacity and spend a longer time building
computational capacity, but to build a higher total of
computational capacity by using more of the total Mbudget.
In this approach, the amount of additional built computational
capacity is:
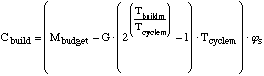 ....(18) ....(18)
and the time then spent building that capacity
is:
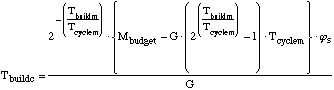 ....(19) ....(19)
A more detailed model would also consider
disassembly capacity. Once the entire Mbudget is
expended, the surge manufacturing capability would be
disassembled, and converted into further computational capacity.
For very large problems, the time to surge computation will be
small compared to the total run time, and thus Trun
can be approximated as:
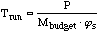 ....(20) ....(20)
While this introduction assumed a simple model of
problem computability, actual approaches must be
algorithm-specific, depending on the problem to be solved.
Additional computational mass will be most useful in running
purely parallel algorithms. Inherently sequential problems may
have algorithm elements, such as pivoting a large matrix, that
can be accelerated with special-purpose hardware, but that will
be sized to the problem and may not provide any further benefit
with further size.
Furthermore, this analysis has assumed that the algorithmic
run size of a problem is known. In general it is not known ahead
of time how long an algorithm must run before it stops. In these
cases a mixed strategy of building additional computational
capacity and additional fabrication capacity in parallel may be
the best strategy. In addition, there are trade-offs between
algorithms, and between specialized computational devices and
general computational devices across the span of computations
during the mission. Special purpose hardware that seems likely to
be used again soon should not be disassembled at the end of the
calculation. An agoric system [Miller &
Drexler, 1988] may be the most reasonable way to handle these
complexities.
Similar calculations can be made for power estimates. Indeed,
the power (and cooling) budget is likely to often be more
restrictive to computational capacity than the mass budget.
While this analysis did not consider the details of the
feedstock mass and how it supported the possible manufacturing
and computer components, that also must be properly handled in a
working system. In physical surging there is always a trade-off
between storing more elemental, widely usable feedstocks such as
small, simple molecules, and storing more specialized units that
can be rapidly combined for functional purposes, such as
prefabricated logic units.
Even for mass fully dedicated to a built computer, some
mechanical rearrangement for specific computations may be
promising. A mechano-electric computer could involve the
mechanical arrangement or rearrangement of pre-defined logic
units, creating a special-purpose electric computer for the
problem at hand much quickly than building it entirely from
scratch, for a process nearly as fast as having the special
purpose computer already on hand. Quantum computing, where the
algorithm depends finely on the physical structure, may be
particularly well suited to this hybrid approach.
Particular instantiations of the logical core architecture
will have their own physical framework. Many different physical
styles can be imagined, but, with the ability to create stable
scaffolding, it should be possible to move between radically
different physical styles over the course of a mission.
For example, imagine a system physically comprised of a
modular space frame and various subsystems attached to the space
frame as "boxes," including attached computers,
molecular manufacturing systems similar to the exemplar
architecture in chapter 14 of [Drexler,
1992a], disassemblers, storage tanks, external sensors, solar
panels, cooling panels, engines, etc. Pipes and cables could run
along the frame, or in conduit within the frame. Locomotion
within the system can be tracked, frame-walking, or both.
A radical physical change would be into a cloud of utility fog
[Hall, 1996], a cloud of small, discrete, inter-grasping units,
plus some additional items in the cloud that perform logical core
architecture functions that pure utility fog omits. To begin, the
space frame system begins disassembling its least necessary
components into raw material, while simultaneously producing
utility foglets. Software for those foglets are loaded from the
Archive, and over time the contents of the space frame archive
are copied into the growing mass of data storage spread across
the foglet computers. The foglets link, holding to each other,
while some attach to what will be the last bit of the old space
frame system. The foglets also distribute power and
communications through and across their cloud. Initially, the
space frame equipment moves parts to the space frame's
disassembler, but at some point in the process, the utility fog
can take over the task of transporting elements to the
disassembler. Since foglets cannot perform general fabrication or
fine disassembly, special subsystems designed to perform these
functions, and embed in the utility fog, must also be produced.
Tiny amounts of material storage can be provided by each foglet.
If the total mass contains too much of some element(s) to be
fully stored across the foglets, then special-purpose storage
containers will also have to be included in the cloud.
The end is a cloud of utility fog, with some general
manufacturing device(s), some foglet disassembly device(s), able
to disassemble even damaged foglets, and possibly some foglet
repair devices embedded in the cloud.
There are many possible frameworks, and corresponding examples
of potential transformations between frameworks.
The system may go through mission phases where there is very
little the system can or should do. For example, if riding a
long-period comet, the system may wish to shut-down for the long
time when it is far from the sun.
The system could hibernate during these times, go to near or
zero operations and zero power for an extended period, and later
restart. To restart, the system must either continue some
function at a low trickle-power level, such as a clock or
observing for restart conditions, or it must be actively
restarted by its environment.
Before simply shutting down, the system may want to surge Data
Storage, reducing nearly everything to data. After hibernation,
the system would reboot from the Archive. This might be a useful
technique when crossing interstellar space near the speed of
light, and thus experiencing a massive radiation load for a fixed
period of time. Since the system is not reviewing and correcting
the Archive data, it will eventually degrade beyond recovery,
setting a limit on how long the system can hibernate. To maximize
potential hibernation time, the data should be in encoded into a
stable media, using error-correcting code. Since computational
capacity can be surged after hibernation, the error correcting
code should use context heavy redundancy, rather than simple data
repetition.
Three example multi-phase space mission profiles, illustrating
different capabilities, are presented. They are asteroid
settlement, Martian terraforming, and an interstellar seed. Each
is described narratively.
Start by launching the system conventionally from Earth. Once
beyond the atmosphere, the system reconfigures so that most of
the mass is dedicated to solar power and ion engines. This will
allow propulsion with very high specific impulse and high
acceleration [Drexler, 1992b], allowing the system to quickly
reach any asteroid in the solar system. Travel to a carbonaceous
asteroid. Once there, begin excavating the asteroid, using the
mass to build up extractive and processing capability. The system
then grows to consume the mass of the asteroid. This larger
system can now be put to many purposes.
For example, if 10% of a 1 km diameter asteroid orbiting at
2.4 AU is converted into the equivalent of a 1 micron thick sheet
of solar panels, computers and cooling, then the structure can
present an area of 5.2 x 107 square km to the sun, and
should be able to generate roughly 1041 bits of
computation per second, if not more with aggressive use of
reversible computation. Note that this physical layout is
compatible with the reversible 3-D mesh structure that Frank
considers "an optimal physically-realistic model for
scalable computers."[Frank, 1997] Using the estimates in
[Moravec, 1988], this is computationally equivalent to roughly
the total brain power of 1026 people, which
significantly exceeds the 1.4 x 1016 people that Lewis
estimates could be supported as biological inhabitants on the
resources of the main belt asteroids [Lewis, 1997]. Even with
significant software inefficiencies, such capacity could quickly
perform large amounts of automated engineering (as defined in [Drexler, 1986a]). An
option is to surge the computers, develop a number of designs,
save those in compact form in the Archive, and then disassemble
most of this computer for other purposes.
Whether or not this quantity of pre-computation is useful, the
system eventually reconfigures itself into a settlement, along
the ideas of O'Neill [O'Neill, 1974], [O'Neill, 1976], [Johnson,
1977], [McKendree,
1996]. It would be convenient for the settlement to be
arranged so that its rotational axis is parallel to its orbital
axis. One advantage is that the system could then grow cables and
provide momentum transfer for solar system traffic to, from, and
through this logical core architecture system.
Over long periods of time, the system might use solar sailing
to put it in a more favorable orbit. This could be less inclined
to the plane of the ecliptic, to ease travel with the rest of the
solar system. It could be more inclined to the plane of the
ecliptic, if there is contention for solar output. It would
probably be more circular, to regularize the received solar flux,
and perhaps closer to the sun, to increase the density of solar
flux. Finally, it would be managed to avoid collisions.
Launch the system from Earth. Once above the atmosphere, it
reconfigures itself, dedicating much of the system mass to solar
sails; using MNT these can have significant capabilities
[Drexler, 1992b], [McKendree, 1997]. This allows the vehicle to
transit to Mars. On approach the system builds an aerobrake, and
is captured into a polar orbit by the Martian atmosphere. The
system then converts the bulk of its mass into a large aperture
mass spectrometer, to map the elemental composition of Mars in
detail. The system might abort its mission at this point,
notifying Earth and waiting for instructions for a new mission,
if it does not find suitable conditions to continue, such as
adequate water.
Assuming the system continues, it then selects one or more
promising landing sites, and reconfigure itself into one or more
atmospheric entry capsules that land on the surface. Building up
from local resources, the system grows itself into an assembly of
inflatable cells that cover the Martian surface with a thin
plastic canopy holding a growing atmosphere, as in [Morgan,
1994]. This allows terraforming Mars while supporting early
shirtsleeve habitability.
This mission profile uses a number of different platforms,
which need not, but could be, implemented using the logical core
architecture.
Launch a system from Earth, which then travels to a Uranus and
enters its atmosphere. The system configures itself into a
balloon structure floating in the atmosphere, mines He3
from the atmosphere, and ultimately rockets out with a payload of
liquefied He3, as sketched in chapter 13 of [Lewis,
1996].
One approach for the next step is to divide into several
daughter systems at this point, and each travel to one of several
different asteroids. For subsequent reasons, this should include
at least one main-belt asteroid, potentially a trojan asteroid,
at least one Kuiper-belt asteroid, and possibly a long-period
comet, if one can be found in an appropriate orbit. Indeed, it
might be helpful if every asteroid selected were an extinct
comet, as it should contain significant quantities of hydrogen.
Bootstrap the system at each location using each asteroid's
resources.
Launch another system from Earth, which transforms the
majority of its mass into a solar sail. That solar sail
decelerates, falling close towards the sun, and then accelerates
strongly during and after its solar fly-by.
Use the asteroids as bases to beam acceleration to the
outgoing vehicle. Many schemes are possible. The one suggested
here is to shine lasers from each asteroid, powered by H-He3
fusion, towards the departing system's solar sail similar to
[Forward, 1984].
The vehicle travels outside the solar system, accelerating to
a significant fraction of the speed of light on a trajectory to a
nearby solar system. Once accelerated, it reconfigures itself,
converting the significant mass fraction of the solar sail into
shielding against the radiation bombardment of the vehicle as it
travels at high speed through the interstellar medium. The system
hibernates, with the archive in a highly recoverable data
redundancy. Most of the Archive should be so structured from the
beginning.
Later in its flight, the system reactivates, and reconfigures
itself into a magsail [Zubrin & Andrews, 1991], a
superconducting loop of current that generates thrust by
deflecting the charged particles in space. This allows the
vehicle to slow down, and incidentally extracting energy (which
thus allows the system to resume maintenance functions). The
system may release probes before fully slowing down, which would
fly through the target system gathering data for broadcast back
to the main system, and use that information to prepare for
arrival. The system arrives at the target star system, surveys
it, and travels to a small body, probably similar to a
carbonaceous asteroid or a comet.
Once there the system bootstraps itself from the local
resources. It then builds a receiver, and listens for data and
instructions to update its mission plan. Meanwhile, it may send
daughter systems to other small bodies, and bootstrap local
capabilities significantly. Subsequent potential actions include
building up information and products based on received
instructions, possibly building local settlements, and building
daughter seeds and sending them on to further star systems.
The "seed" that crosses the interstellar space may
well mass significantly less than a human being, and nonetheless
be able to support the transmission of significant numbers of
humans, from their information content transporting across the
interstellar divide [Reupke, 1992], by bootstrapping to equipment
that receives and assembles them.
This is similar to the Freitas strategy for galactic
exploration [Freitas, 1980]. Beyond the technical details of
implementation, the major difference is that the Freitas probes
were meant to be search probes, with fixed programming replicated
across the galaxy, whereas in this mission each vehicle arrives
as the first step in creating a local homestead, fully benefiting
from the resources of each system and creating a space faring
civilization of communicating, settled solar systems. Inhabited
civilization closely follows the frontier, and over time can
refine the programming of the leading edge probes.
A logical core architecture system is similar to a computer,
in that it has the intrinsic capability for a tremendous range of
function beyond any particular preplanned functions specifically
intended for a given mission. Thus, when confronted by an
unplanned challenge, the logical core architecture may be able to
take action outside its original mission scope to adequately
respond to the challenge. This could involve producing novel
components for its interface layer, beyond what is simply
catalogued in the Archive, or even reconfiguring the system to
implement some novel tactic.
Given sufficient advances in automated engineering [Drexler, 1986a], novel
components for the interface layer could be designed by the
system, in response to the challenge, and even more radical
responses might be autonomously derivable.
These mission profiles have been described above as if they
ran entirely autonomously, without human intervention. While such
a capability may be desirable, especially for interstellar
missions, it will often be unnecessary, and adds to the technical
challenge. In many cases, the missions could run under manned
mission control.
When doing so, the data archive effectively includes all the
data and software that mission control has or can generate. JPL
has demonstrated massive reprogramming of vehicles in space, and
in concert with logical core architecture vehicles a highly
skilled mission control could achieve significant results at a
distance.
Also, the interface layer could provide life support, allowing
the vehicle to be manned, and under local control.
For all the above operations, the purpose of the system is
ultimately implemented by the interface layer, with the inner
layers merely providing the support necessary for the system to
survive and implement its interface layer. Another potential
purpose for a logical core architecture system, however, is the
maintenance, or the operational continuity, of particular
information held within the logical core. The interface layer
then implements a subsidiary purpose, survival within the
environment of the system.
This purpose could be applied to many elements of information
that are valued. To take an extreme, the idea has been suggested
[Moravec, 1988], [Minsky,
1994] that the total informational content of a human's
mental processes could be abstracted from their biological
substrate, and implemented in computers. Estimates for the
necessary computational power [Moravec, 1988], [Merkle 1989],
fall well below the 1015 MIPS Drexler conservatively
estimates [Drexler,
1992a] is feasible for an MNT-based mechanical computing
system, let alone more advanced computers MNT may enable [Merkle
& Drexler, 1996].
Note, if maintenance or the operational continuity of an
uploaded mental system is a desired purpose, then one should also
consider the costs and benefits of multiple dispersed copies.
The definition of the logical core architecture sets the
framework for many open questions. Entire flowdowns of
increasingly detailed designs remain. Indeed, since systems
should be able to reconfigure between radically different
physical implementations of the logical core architecture, a
range of different versions needs to be designed.
[McKendree,
1996] discusses how to grapple with the potential of the
future through a hierarchy of technology, system designs,
operational concepts, and grand strategy. As various
implementations of the logical core architecture are developed,
we need corresponding operational concepts, describing how those
approaches would execute desirable missions. Validation of those
operational concepts by analysis should then prompt thinking
about the sorts of strategies such systems enable or require.
Two specific questions raised by the architecture include,
what is the minimal system mass to implement a logical core
architecture system, and does a robot bush [Moravec, 1988]
contain sufficient intrinsic capability such that it is an
implementation of the logical core architecture?
In the stepwise refinement [Rechtin & Maier, 1997] of this
architecture, general operating policy questions loom large.
Surge performance with time remains to be derived for various
non-linear functions of performance with subsystem mass. Beyond
replacement on failure, the maintenance policy must investigate
scheduled replacement, which can be very powerful when using
subsystems with failure rates that increase with time, like the
exemplar architecture in [Drexler,
1992a].
Design remains for efficient computation algorithms that
integrate the potential for surge computation and surge data
caching. Heuristics for good practice, let alone optimal
algorithms, are unclear. Algorithms should be examined that use
in-progress fabrication of selectable special-purpose
manufacturing capacity. For example, the simple model presented
in 4.2 only works when the same special-purpose computational
devices are useful throughout the run of the algorithm, whereas
the utility of a particular piece of computational hardware may
not be evident until partially through an algorithm. Furthermore,
some computational devices will scale in an algorithm, whereas
other devices (e.g., a device to invert an array sized to the
problem in one clock cycle) may have no utility until a large
increment of computational hardware is complete.
There are many operationally trade-offs that are expressions
of the general trade-off between using less efficient general
purpose equipment, and carrying various amounts more efficient
special purpose equipment. These trade-offs become more
complicated when also considering the possibility of surging
various capacities. It requires balancing mass budgets and
different quantities of various equipment, along with power and
response timelines, and still leaves the question of balancing
between short-term use of specialized equipment versus potential
reuse of more generalized equipment.
If uploading is possible, and uploading into a logical core
architecture is desirable, then an open policy question is
"would it be preferable to devote one Logical Core
Architecture system each to one upload, or to host a colony of
uploads within one system?"
Looking more generally at the field of MNT-based system
design, new functions require definition of new performance
metrics. Many forms of performance have standard metrics, such as
resistance which measures ability to carrying current, yield
stress which measures a material's ability to carrying force,
capacitance which measures ability to store charge, maximum
velocity, vehicle range, and for estimating computing speed,
instructions per second. An important category of MNT-based
performance is "morphability," the ability of the
system to reconfigure itself, but there are no standardized
metrics defined for this. Many different polymorphic systems are
possible, and metrics are needed to quantify them. More than one
metric may be required. Issues that should be addressed include
how quickly can the system change form, how many different forms
can the system change between, and how different in dimension,
characteristic and function are the forms the system can change
between. At least some metrics should integrate across forms, to
consider, for example, a system that can quickly change amongst a
small set of forms and that can more slowly change amongst a
wider set of forms.
Given a capability for fairly general purpose manufacturing
and of disassembly, as molecular nanotechnology promises, along
with sufficient control, and systems with a logical core
architecture are feasible. This four-layer architecture is
defined. It maintains a purely informational center, hosts that
and other core system functions in replaceable and radically re
configurable hardware, is able to surge the capacity of any core
function, and interacts with its environment though instantiated
components from a potentially vast set of virtual components. The
architecture offers the potential of long-life through
remanufacture of subsystems. It is "a pile of atoms. And
when you want something else, it rearranges itself into another
pile of atoms" [Merkle, 1994].
The logical core architecture forms a basis for developing
system concepts that exploit the particular capabilities of MNT.
As such, it provides another step to help in thinking about the
future that will be unfold from the development of MNT.
Finally, this architecture is applicable for purposes well
beyond space operations.
- [Axelband, Elliot, 1994] Personal communications, 1994.
- [Drexler, K.E., 1986a] Engines of Creation:
The Coming Era of Nanotechnology, Doubleday, New
York, 1986.
- [Drexler, K.E., 1986b] "Molecular Engineering,
Assemblers and Future Space Hardware," American
Astronautics Society, AAS-86-415.
- [Drexler, K.E., 1988a] "Nanotechnology and the
Challenge of Space Development," Proceedings of the
1988 National Space Society Conference.
- [Drexler, K.E., 1992a] Nanosystems:
Molecular Machinery, Manufacturing, and Computation,
Wiley Interscience, 1992.
- [Drexler, K.E., 1992b] "Molecular Manufacturing for
Space Systems: An Overview," Journal of the British
Interplanetary Society, Vol. 45, No. 10, pp.
401-405,1992.
- [Drexler, K.E., 1995] "Molecular Manufacturing as a
Path to Space," Prospects in Nanotechnology: Toward
Molecular Manufacturing, John Wiley & Sons, pp.
197-205, 1995.
- [Drexler, K.E., C. Peterson, G. Pergamit, 1991] Unbounding
the Future: The Nanotechnology Revolution, William
Morrow, 1991.
- [Frank, Michael P., 1997] "Ultimate Theoretical
Models of Nanocomputers," paper for The Fifth
Foresight Conference on Molecular Nanotechnology, paper
available at http://www.ai.mit.edu/~mpf/Nano97/paper.html,
1997.
- [Freitas, R.A., Jr, 1980] "A Self-Reproducing
Interstellar Probe," Journal of the British
Interplanetary Society, Vol. 33, pp. 251-264, 1980.
- [Forward,
Robert L., 1984] "Roundtrip Interstellar Travel
Using Laser-Pushed Lightsails," Journal of
Spacecraft and Rockets, Vol. 21, No. 2, pp. 187-195,
1984.
- [Hall, John Storrs, 1996] "Utility
Fog: The Stuff That Dreams Are Made Of," in
Nanotechnology, Speculations on Global Abundance, B. C.
Crandall, editor, MIT Press, Cambridge, Massachusetts,
1996.
- [Johnson, R D, Holbrow C, 1977] Space
Settlements: A Design Study, NASA SP-413, US
Government Printing Office, 1977.
- [Lewis, John S., 1996] Mining
the Sky. Helix Books, Addision Wesley, 1996.
- [Lewis, John S., 1997] "Resources of the
Asteroids," Journal of the British
Interplanetary Society, Vol. 50, pp. 51-58, 1997.
- [McKendree, Thomas, 1992] The Role of Systems
Architecting, and How it Relates to Systems
Engineering", Proceedings 2nd Annual NCOSE
Symposium, INCOSE,1992.
- [McKendree, Thomas, 1996] "Implications
of Molecular Nanotechnology Performance Parameters on
Previously Defined Space Systems",
Nanotechnology Vol. 7 No. 3, pp. 204-209, 1996.
- [McKendree, Thomas, 1997] "Balancing Molecular
Nanotechnology-Based Space Transportation and Space
Manufacturing Using Location Theory: A Preliminary
Look", Space Manufacturing 11, Barbara Faughnan
(ed.), Space Studies Institute, 1997.
- [Merkle, Ralph,
1994] Personal communications, 1994.
- [Merkle, Ralph, 1989] "Energy
Limits on the Computational Power of the Human Brain,"
Foresight Update, No. 6,1989.
- [Merkle, Ralph, and K. Eric Drexler, 1996] "Helical
Logic," Nanotechnology, Vol. 7, No. 4, pp.
325-339,1996.
- [Miller, Mark S. and K. Eric Drexler, 1988] "Incentive
Engineering for Computational Resource Management,"
The Ecology of Computation, B. A. Huberman (Ed.), 1988.
- [Minsky, Marvin, 1994] "Will
Robots Inherit the Earth?," Scientific American,
Oct 1994.
- [Moravec, Hans,
1988] Mind Children, Harvard University Press, 1988.
- [Morgan, Charles R., 1994] "Terraforming with
Nanotechnology," Journal of the British
Interplanetary Society, Vol. 47, pp. 311-318, 1994.
- [O'Neill, G.K., 1974b] "The Colonization of
Space," Physics Today, pp. 32-40, September 1974.
- [O'Neill, G.K., 1976] The High Frontier, Space Studies
Institute Press, 1989.
- [Rechtin, Eberhardt, and Mark
W. Maier, 1997] The Art of Systems Architecting, CRC
Press, 1997.
- [Reupke, William A., 1992] "Efficiently Coded
Messages Can Transmit the Information Content of a Human
Across Interstellar Space," Acta Astronautica, Vol.
26, No. 3/4, pp. 273-276, 1992.
- [Thorson, Mark, 1991] "Kram: The Universal
Material," unpublished manuscript, 1991.
- [Zubrin, R.M., D.G. Andrews, 1991] "Magnetic Sails
and Interplanetary Travel," Journal of Spacecraft
and Rockets, Vol. 28, No. 2, pp. 197-203, 1991.
|